TimeSeries Database(TSDB) v1.3.0
TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers Measure and Stream relevant data.
In TSDB, the data in a group is partitioned based on the time range of the data. The segment size is determined by the segment_interval of a group. The number of segments in a group is determined by the ttl of a group. A new segment is created when the written data exceeds the time range of the current segment. The expired segment will be deleted after the ttl of the group.
More than the time series data model, TSDB also provides a schema-less and non-time-series data type, Property. The Property data type is used to store the document which contains several tags. The Property data is an independent group that contains only shards, without segment_interval, ttl, or other time-series-related features.
Segment
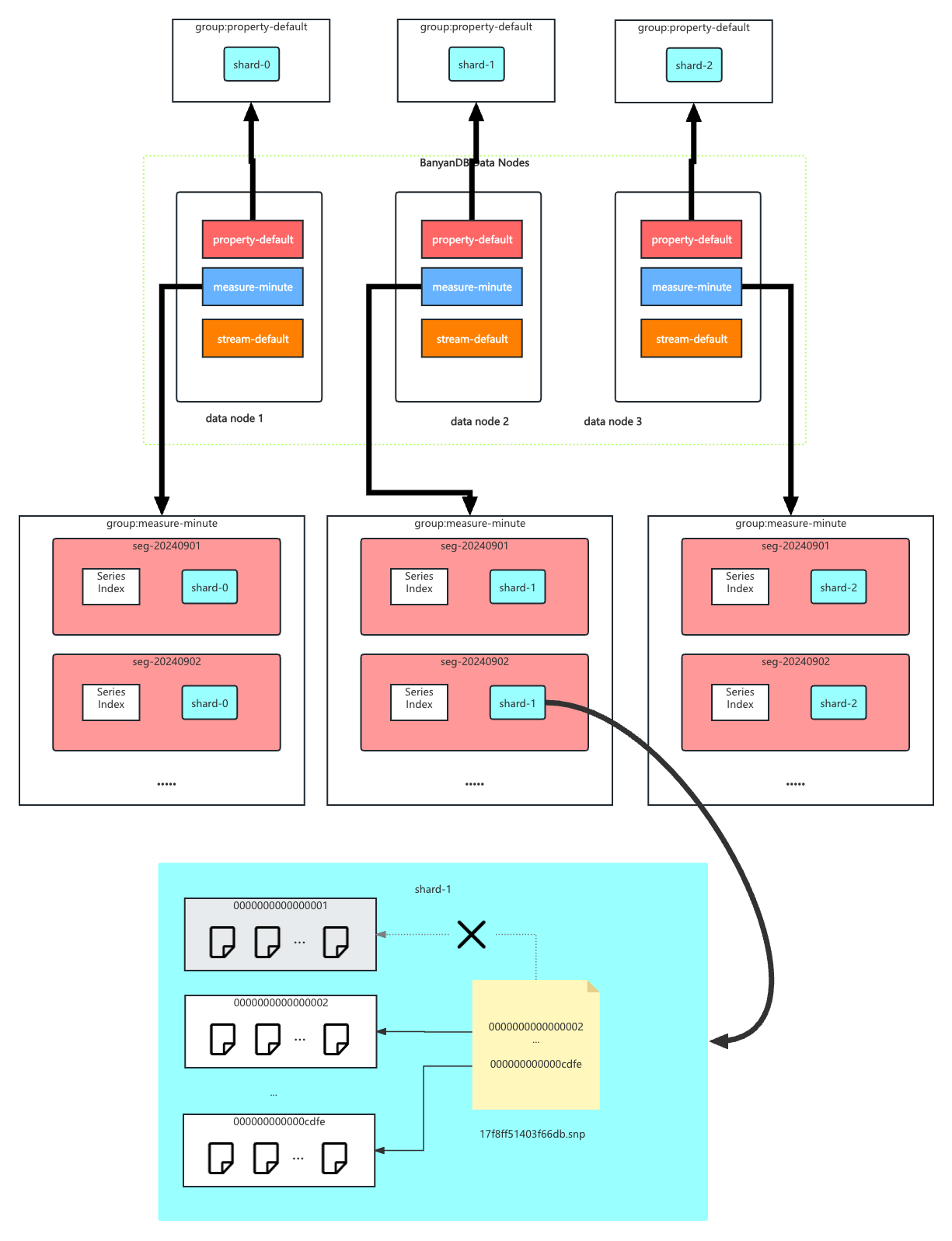
In each segment, the data is spread into shards based on entity. The series index is stored in the segment, which is used to locate the data in the shard.
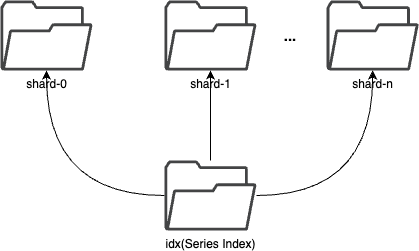
Shard
Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed.
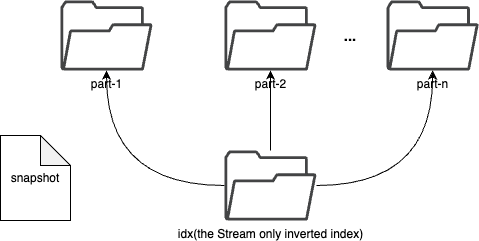
In Stream or Measure, Each shard is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new part. For data of the Stream type, the inverted indexes generated based on the indexing rules are also stored in the segment.
Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. The shard contains xxxxxxx.snp to record the validity of parts. In the chart, 0000000000000001 is removed from the snapshot file, which means the part is invalid. It will be cleaned up in the next flush or merge operation.
In Property, the shard is implemented by the inverted index. Users could filter data by the tag.
Inverted Index
The inverted index is used to locate the data in the shard. For measure, it is a mapping from the term to the series id. For stream, it is a mapping from the term to the timestamp.
For property, all the content of a property is stored as a _source field in the inverted index. group, name, id and tags are only indexed in the inverted index.
The inverted index stores snapshot file xxxxxxx.snp to record the validity of segments. In the chart, 0000000000000001.seg is removed from the snapshot file, which means the segment is invalid. It will be cleaned up in the next flush or merge operation.
The segment file xxxxxxxx.seg contains the inverted index data. It includes four parts:
- Tags: The mapping from the tag name to the dictionary location.
- Dictionary: It’s a FST(Finite State Transducer) dictionary to map tag value to the posting list.
- Posting List: The mapping from the tag value to the series id or timestamp. It also contains a location info to the stored tag value.
- Stored Tag Value: The stored tag value.
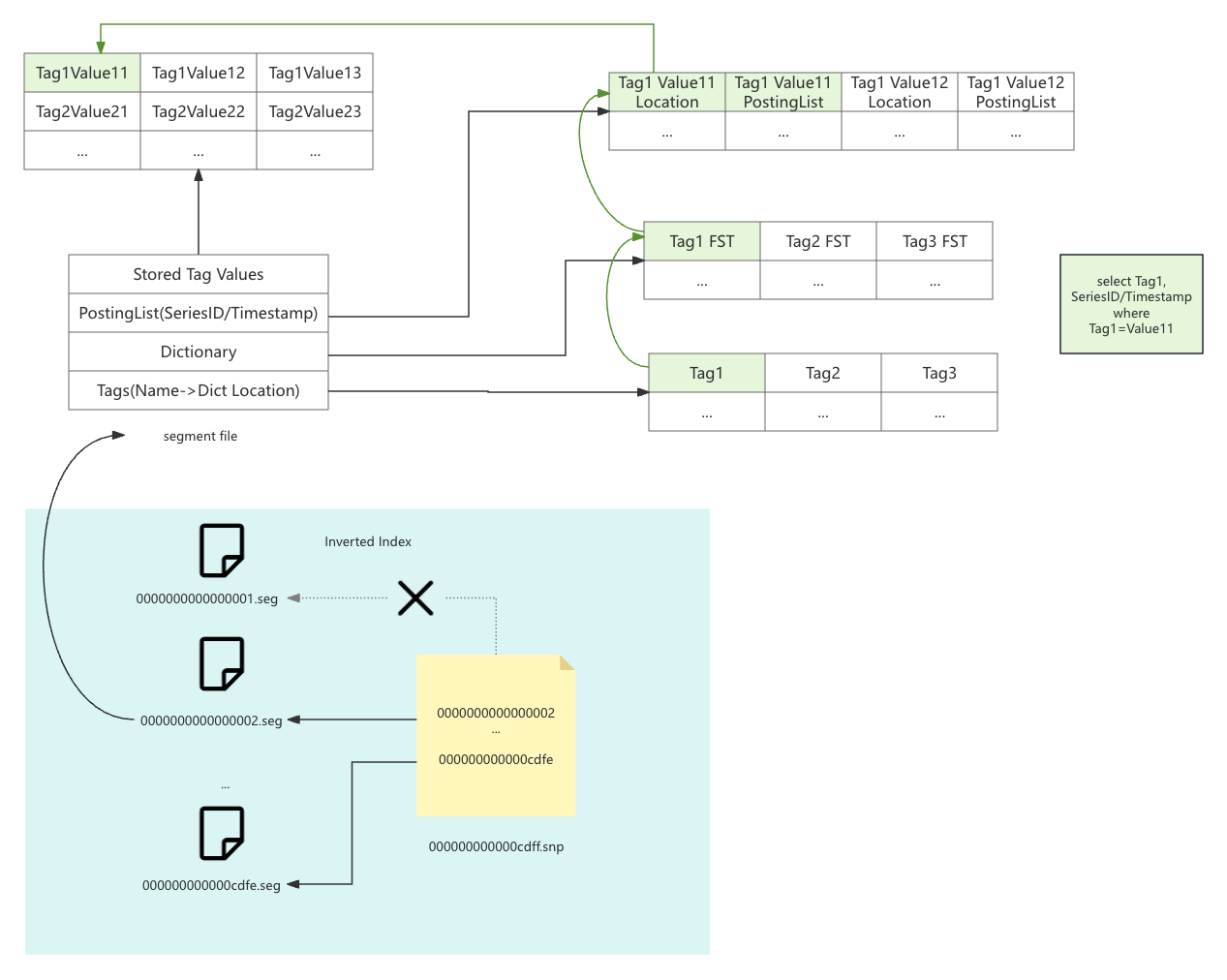
If you want to search Tag1=Value1, the index will first search the Tags part to find the dictionary location of Tag1. Then, it will search the Dictionary part to find the posting list location of Value1. Finally, it will search the Posting List part to find the series id or timestamp. If you want to fetch the tag value, it will search the Stored Tag Value part to find the tag value.
Part
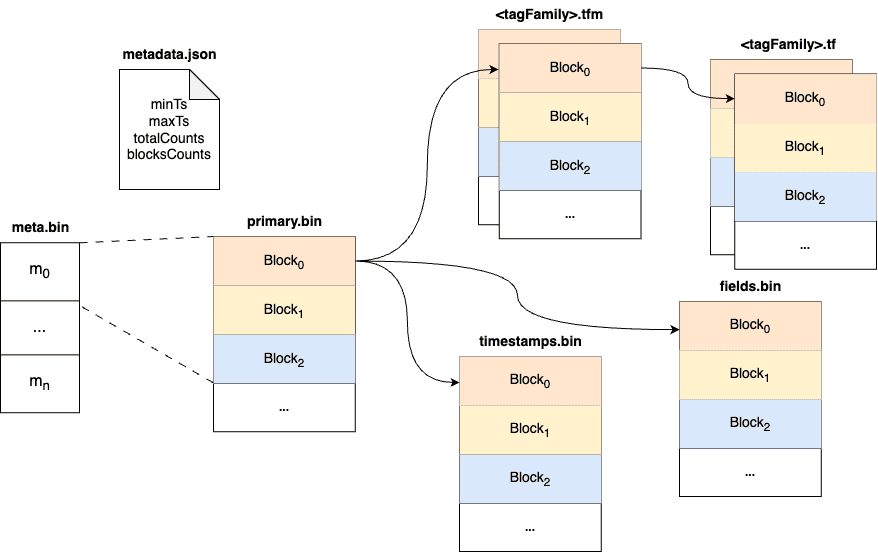
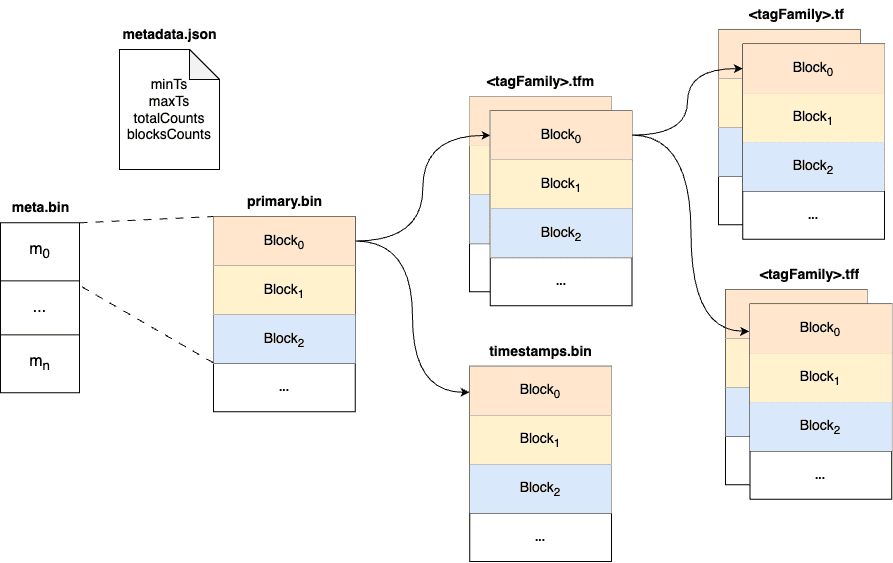
Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the timestamps.bin file, tags are organized in persistent tag families as various files with the .tf suffix, and fields are stored separately in the fields.bin file.
In addition, each part maintains several metadata files. Among them, metadata.json is the metadata file for the part, storing descriptive information, such as start and end times, part size, etc.
The meta.bin is a skipping index file that serves as the entry file for the entire part, helping to index the primary.bin file.
The primary.bin file contains the index of each block. Through it, the actual data files or the tagFamily metadata files ending with .tfm can be indexed, which in turn helps to locate the data in blocks.
Notably, for data of the Stream type, since there are no field columns, the fields.bin file does not exist, while the rest of the structure is entirely consistent with the Measure type.
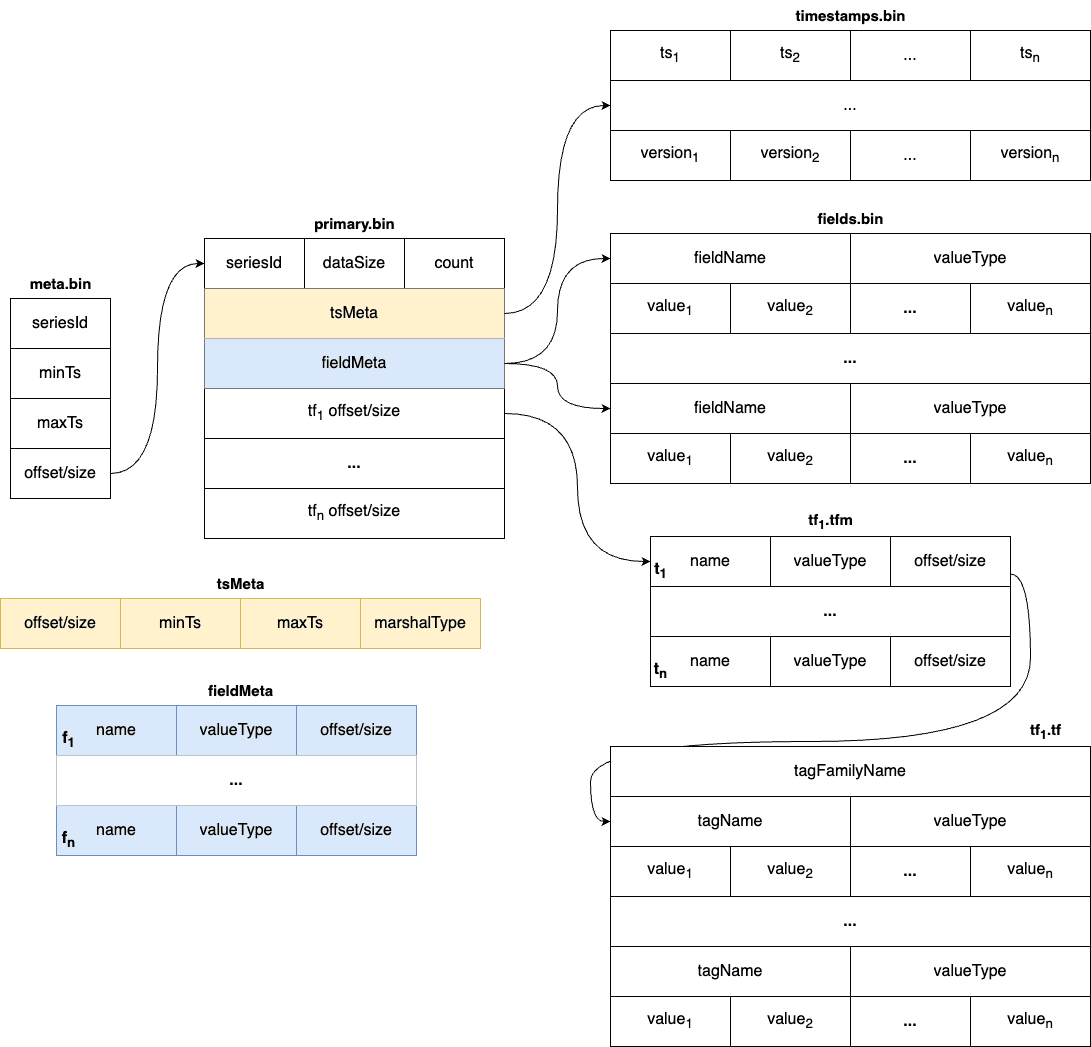
Block
Each block holds data with the same series ID. The max size of the measure block is controlled by data volume and the number of rows. Meanwhile, the max size of the stream block is controlled by data volume. The diagram below shows the detailed fields within each block. The block is the minimal unit of TSDB, which contains several rows of data. Due to the column-based design, each block is spread over several files.
In measure’s timestamp file, there are version fields to record the version of the data. The version field is used to deduplicate. It determine the latest data when the data’s timestamp are identical. Only the latest data will be returned to the user.
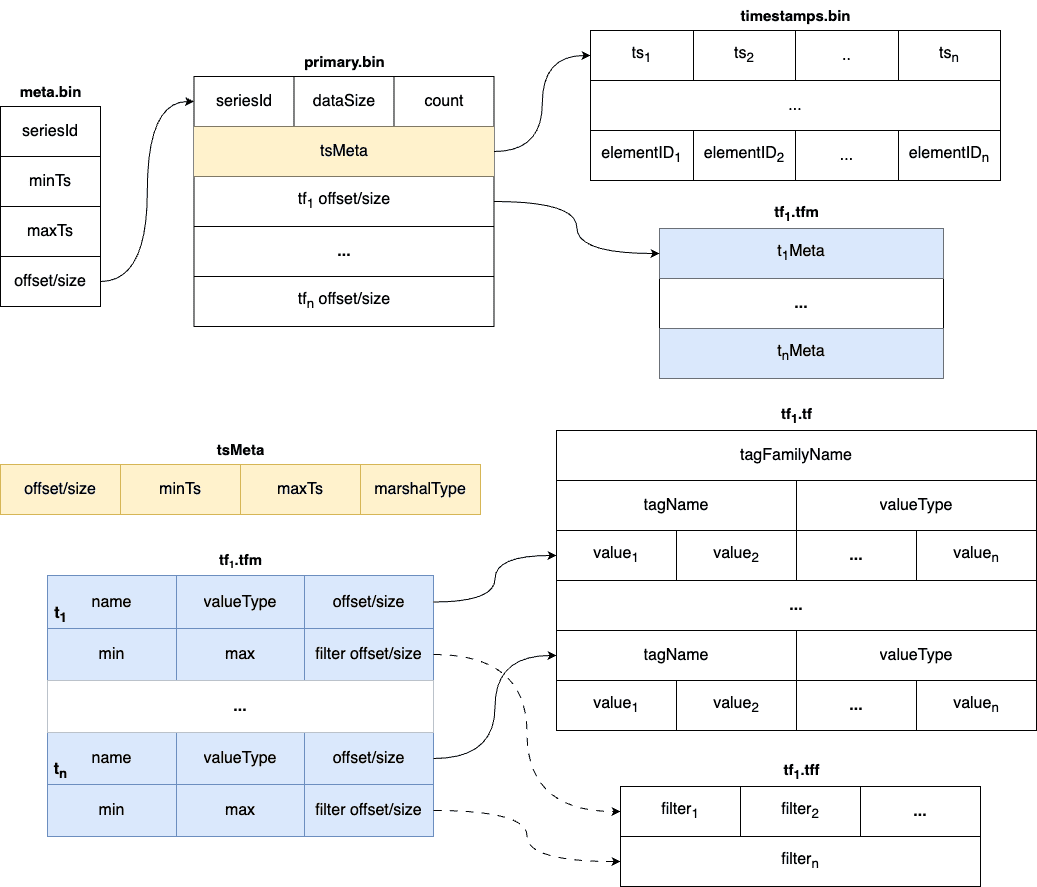
Unlike the measure, there are element ids in the stream’s timestamp file. The element id is used to identify the data of the same series. The data with the same timestamp but different element id will both be stored in the TSDB. This introduces a series of new files, named “.tff”, which contain bloom filters for each tag, enabling efficient skipping of irrelevant data. Additionally, min/max fields are added to the “.tfm” file to further aid in skipping blocks.
Write Path
The write path of TSDB begins when time-series data is ingested into the system. TSDB will consult the schema repository to check if the group exists, and if it does, then it will hash the SeriesID to determine which shard it belongs to.
Each shard in TSDB is responsible for storing a subset of the time-series data. The shard also holds an in-memory index allowing fast lookups of time-series data.
When a shard receives a write request, the data is written to the buffer as a memory part. Meanwhile, the series index and inverted index will also be updated. The worker in the background periodically flushes data, writing the memory part to the disk. After the flush operation is completed, it triggers a merge operation to combine the parts and remove invalid data.
Whenever a new memory part is generated, or when a flush or merge operation is triggered, they initiate an update of the snapshot and delete outdated snapshots. The parts in a persistent snapshot could be accessible to the reader.
Read Path
The read path in TSDB retrieves time-series data from disk or memory, and returns it to the query engine. The read path comprises several components: the buffer and parts. The following is a high-level overview of how these components work together to retrieve time-series data in TSDB.
The first step in the read path is to perform an index lookup to determine which parts contain the desired time range. The index contains metadata about each data part, including its start and end time.
If the requested data is present in the buffer (i.e., it has been recently written but not yet persisted to disk), the buffer is checked to see if the data can be returned directly from memory. The read path determines which memory part(s) contain the requested time range. If the data is not present in the buffer, the read path proceeds to the next step.
The next step in the read path is to look up the appropriate parts on disk. Files are the on-disk representation of blocks and are organized by shard and time range. The read path determines which parts contain the requested time range and reads the appropriate blocks from the disk. Due to the column-based storage design, it may be necessary to read multiple data files.