Persistence Storage
Persistence storage is used for unifying data of BanyanDB persistence, including index, and data collected from skywalking and other observability platforms or APM systems. It provides various implementations and IO modes to satisfy the need of different components. BanyanDB provides a concise interface that shields the complexity of the implementation from the upper layer. By exposing necessary interfaces, upper components do not need to care how persistence is implemented and avoid dealing with differences between different operating systems.
Architecture
BanyanDB uses third-party storage for actual storage, and the file system shields the differences between different platforms and storage systems, allowing developers to operate files as easily as the local file system without worrying about specific details.
For different data models, stored in different locations, such as for meta data, BanyanDB uses a local file system for storage.
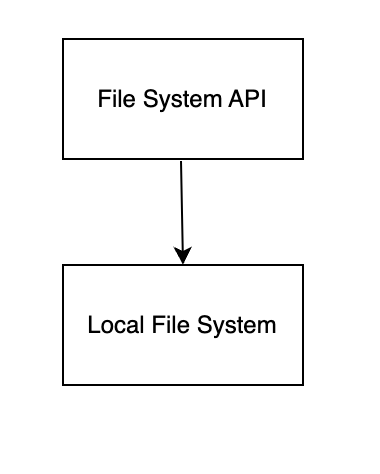
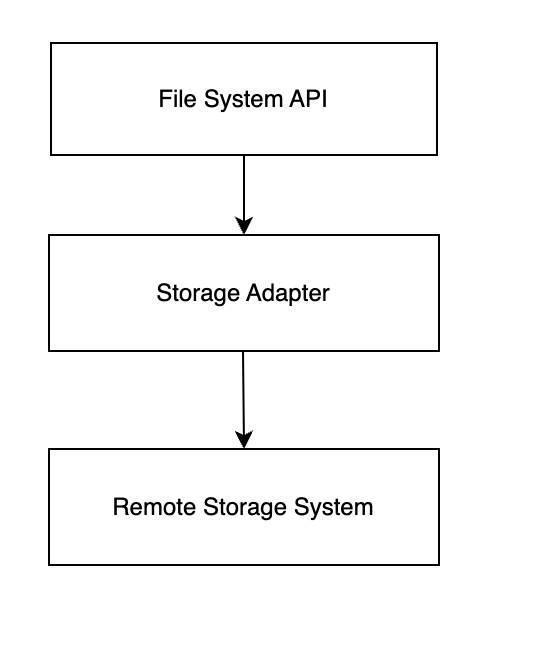
For index and data, the architecture of the file system is divided into three layers.
- The first layer is the API interface, which developers only need to care about how to operate the remote file system.
- The second layer is the storage system adapter, which is used to mask the differences between different storage systems.
- The last layer is the actual storage system. With the use of remote storage architecture, the local system can still play its role and can borrow the local system to speed up reading and writing.
IO Mode
Persistence storage offers a range of IO modes to cater to various throughput requirements. The interface can be accessed by developers and can be configured through settings, which can be set in the configuration file.
Io_uring
Io_uring is a new feature in Linux 5.1, which is fully asynchronous and offers high throughput. In the scene of massive storage, io_uring can bring significant benefits. The following is the diagram about how io_uring works.
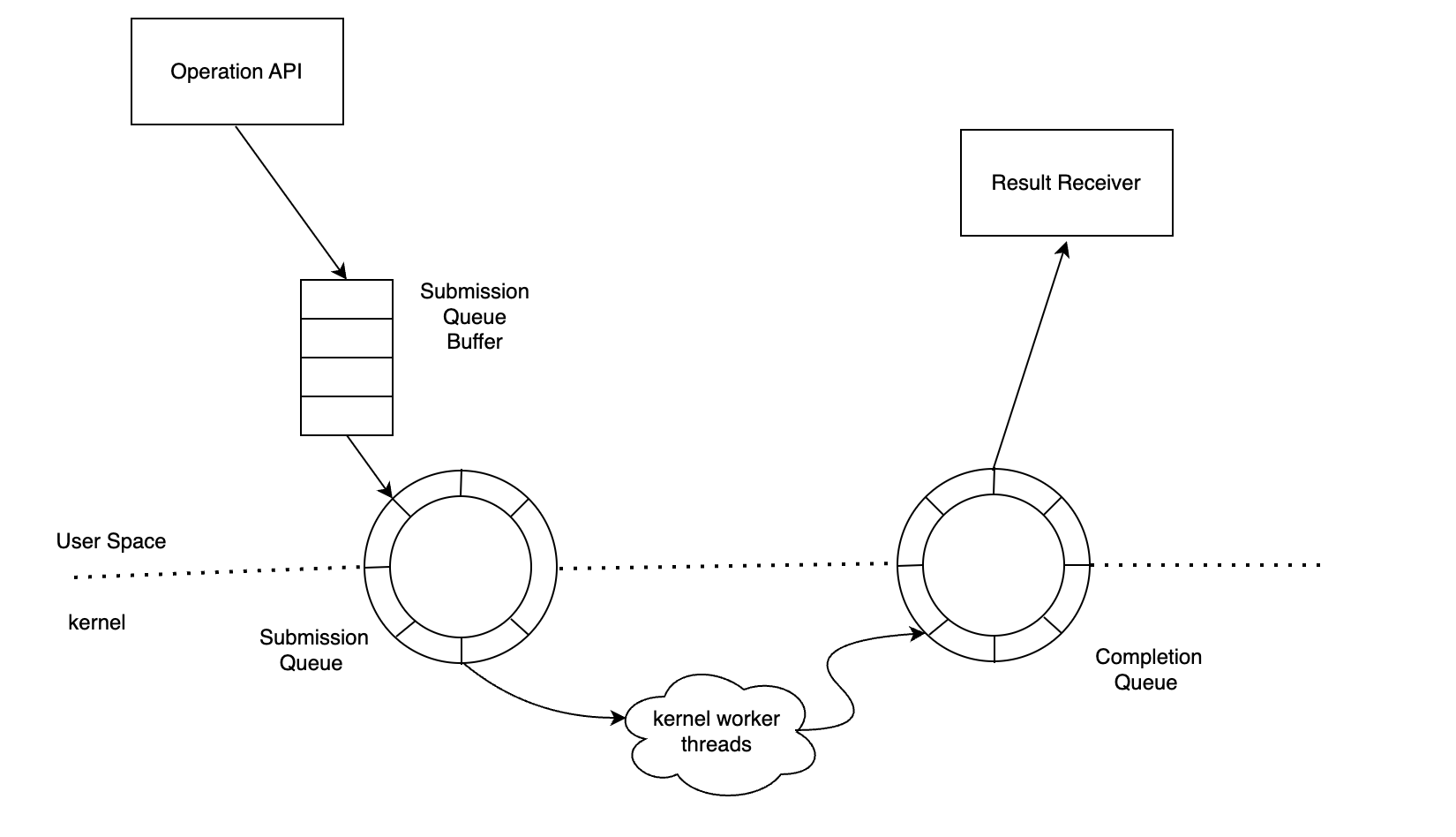 If the user sets io_uring for use, the read and write requests will first be placed in the submission queue buffer when calling the operation API. When the threshold is reached, batch submissions will be made to SQ. After the kernel threads complete execution, the requests will be placed in the CQ, and the user can obtain the request results.
If the user sets io_uring for use, the read and write requests will first be placed in the submission queue buffer when calling the operation API. When the threshold is reached, batch submissions will be made to SQ. After the kernel threads complete execution, the requests will be placed in the CQ, and the user can obtain the request results.
Synchronous IO
The most common IO mode is Synchronous IO, but it has a relatively low throughput. BanyanDB provides a nonblocking mode that is compatible with lower Linux versions.
Operation
File
Create
Create the specified file and return the file descriptor, the error will happen if the file already exists. The following is the pseudocode that calls the API in the go style.
param:
name: The name of the file.
permisson: Permission you want to set. BanyanDB provides three mode: Read, Write, ReadAndWrite. you can use it as Mode.Read.
return: The file instance, can be used for various file operations.
CreateFile(name String, permission Mode) (File, error)
Write
BanyanDB provides two methods for writing files. Append mode, which adds new data to the end of a file. BanyanDB also supports vector Append mode, which supports appending consecutive buffers to the end of the file. Flush mode, which flushes all data to one file. It will return an error when writing a directory, the file does not exist or there is not enough space, and the incomplete file will be discarded. The flush operation is atomic, which means the file won’t be created if an error happens during the flush process. The following is the pseudocode that calls the API in the go style.
For append mode:
param:
buffer: The data append to the file.
Actual length of written data.
File.Write(buffer []byte) (int, error)
For vector append mode:
param:
iov: The data in consecutive buffers.
return: Actual length of written data.
File.Writev(iov *[][]byte) (int, error)
For flush mode:
param:
buffer: The data append to the file.
permisson: Permission you want to set. BanyanDB provides three mode: Read, Write, ReadAndWrite. you can use it as Mode.Read.
return: Actual length of flushed data.
Write(buffer []byte, permission Mode) (int, error)
Delete
BanyanDB provides the deleting operation, which can delete a file at once. it will return an error if the directory does not exist or the file not reading or writing.
The following is the pseudocode that calls the API in the go style.
DeleteFile(name string) (error)
Read
For reading operation, two read methods are provided: Reading a specified location of data, which relies on a specified offset and a buffer. And BanyanDB supports reading contiguous regions of a file and dispersing them into discontinuous buffers. Read the entire file, BanyanDB provides stream reading, which can use when the file is too large, the size gets each time can be set when using stream reading. If entering incorrect parameters such as incorrect offset or non-existent file, it will return an error. The following is the pseudocode that calls the API in the go style.
For reading specified location of data:
param:
offset: Read begin location of the file.
buffer: The read length is the same as the buffer length.
return: Actual length of reading data.
File.Read(offset int64, buffer []byte) (int, error)
For vector reading:
param:
iov: Discontinuous buffers in memory.
return: Actual length of reading data.
File.Readv(iov *[][]byte) (int, error)
For stream reading:
param:
buffer: Every read length in the stream is the same as the buffer length.
return: A Iterator, the size of each iteration is the length of the buffer.
File.StreamRead(buffer []byte) (*iter, error)
Get size
Get the file written data’s size and return an error if the file does not exist. The unit of file size is Byte. The following is the pseudocode that calls the API in the go style.
return: the file written data’s size.
File.Size() (int, error)
Close
Close File.The following is the pseudocode that calls the API in the go style.
File.Close() error